Wyczytałem, że cielak antylopy gnu może chodzić już kilka minut po swoich narodzinach. Pomyślałem sobie, że to imponujące. Później zacząłem oglądać dwa przykłady, na których sztuczna inteligencja uczy się tego, w jaki sposób może dostać się z punktu A do punktu B. Jej narzędziem jest „ciało”, które dostaje od człowieka i którym musi operować w symulowanym świecie (trochę jak Matrix, ale to tylko moje skojarzenie…). Pomyślałem sobie, że to fajne i zabawne… z czasem było podobnie jak z antylopą gnu, tzn. w końcu doszedłem to wniosku, że to imponujące.
DeepMind
Proces powstawania zdolności do poruszania się w bogatym środowisku, oto moja próba przetłumaczenia tytułu pracy pochodzącej od DeepMind, czyli „Emergence of Locomotion Behaviours in Rich Environments”. Gdybym to ja mógł coś zaproponować, byłoby to raczej „zabawne filmiki ze śmiesznym ludzikiem, który uczy się chodzić”, ale… może to i lepiej, że nikt mnie nie pytał o tytuł.
We wstępie możemy wyczytywać, że uczenie przez wzmacnianie (ang. reinforcement learning) z zasady pozwala na naukę złożonych zachowań, poprzez wykorzystanie prostych sygnałów będących nagrodą. Jednak w praktyce dość powszechne ma być staranne projektowanie funkcji nagrody, tak aby zachęcać do osiągania określonego rodzaju rozwiązania, albo do pozyskiwania go z danych demonstracyjnych. W tym wypadku ludzie z DeepMind obrali za cel zdolność do poruszania się, a nagroda była powiązana z postępami w przemieszczaniu się do przodu.
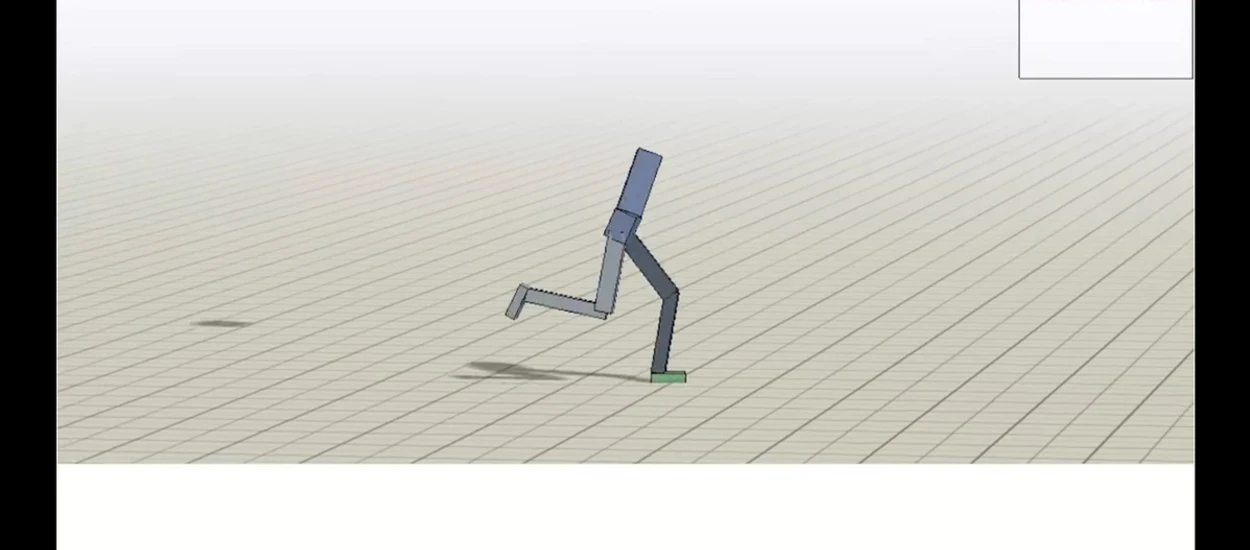
Bogate środowisko, które zostało wypełnione różnymi przeszkodami i terenem o różnej charakterystyce, pomaga w promowaniu nauki złożonych ruchów. Agent sam nauczył się takich rzeczy jak bieganie, skakanie, czy kucanie. Został jedynie wyposażony w wirtualne czujniki, informujące go o sytuacji, np. czy aktualnie model jego ciała stoi w pionie.
Fajnie, że tak sobie z tym wszystkim radzi. To dziwne widzieć jak symulowana postać porusza się w bardzo nietypowy sposób, ponieważ okazało się to być dobrą metodą (nam nie przyszłoby do głowy, żeby dziko wymachiwać ręką dla uzyskania lepszej równowagi), ale z drugiej strony to imponujące, że agent doszedł do tego wszystkiego samodzielnie i często radzi sobie nawet w bardzo niesprzyjających warunkach.
The DeepLoco project
The DeepLoco project jest realizowany przez Xue Bin Peng, Glen Berseth oraz Michiel van de Panne z University of British Columbia, a także przez KangKang Yin z National University of Singapore. To seria eksperymentów wykorzystujących uczenie pogłębione (deep learning) w celu… nauki poruszania się w symulowanym środowisku. Mamy tu do czynienia z tzw. „low-level controllers”, które odpowiadają za uzyskanie podstawowego chodu oraz „high-level controllers”, które podejmują decyzje oparte na otoczeniu, w którym znajduje się agent. Wszystko zostało wytrenowane za pośrednictwem uczenia pogłębionego, a efekty są… całkiem fajne:
Truman Show w wirtualnym świecie
Szkoda, że nie możemy zobaczyć czegoś na podobnej zasadzie, ale w zdecydowanie bardziej zaawansowanej formie. Pomyślałem sobie, że można by stworzyć coś na wzór Truman Show, ale byłaby to jedna wielka symulacja, w której agent uczy się… życia w świecie takim jaki mamy np. w grach z serii GTA.
Źródło 1, 2, 3, 4
Hej, jesteśmy na Google News -
Obserwuj to, co ważne w techu