Autorem tekstu jest Dorota Konowrocka
Page i Brin nigdy nie ukrywali, że najważniejszym celem projektu Google Books nie jest udostępnienie milionów książek czytelnikom, lecz wyekstrahowanie z nich zgromadzonej przez ludzkość wiedzy, o czym pisze między innymi Steven Levy w opublikowanej w 2011 ro...
Autorem tekstu jest Dorota Konowrocka
Page i Brin nigdy nie ukrywali, że najważniejszym celem projektu Google Books nie jest udostępnienie milionów książek czytelnikom, lecz wyekstrahowanie z nich zgromadzonej przez ludzkość wiedzy, o czym pisze między innymi Steven Levy w opublikowanej w 2011 roku książce pt. „In the Plex: How Google Thinks, Works, and Shapes Our Lives”. Jednym ze służących temu celowi narzędzi jest Ngram Viewer 2.0, dostępny na stronie books.google.com/ngrams, który umożliwia prześledzenie częstotliwości występowania poszczególnych wyrazów i fraz w opublikowanych po 1800 roku książkach. Do tej pory Google udało się zeskanować 20 milionów książek, czyli mniej więcej jedną siódmą wszystkich książek opublikowanych od czasów wynalezienia ruchomej czcionki. Od udostępnienia Ngram Viewera mijają właśnie dwa lata, a prace nad nim nieustannie postępują.
Kogo obchodzi, jak często piszemy o wojnie i technologii?
Początkowo Ngram Viewer miał służyć głównie historykom i językoznawcom, w szczególności wykorzystującym tzw. korpusy językowe, czyli po prostu zbiory tekstów ‒ popularnonaukowych, beletrystycznych, prasowych, użytkowych itd. ‒ służące badaniom lingwistycznym dotyczącym na przykład częstotliwości występowania danego typu konstrukcji składniowych w danym języku. Okazało się, że narzędziem z równym specjalistom entuzjazmem zainteresowali się zwykli śmiertelnicy. Swoją drogą, końcówka roku sprzyja tego rodzaju podsumowaniom.
Dlaczego Ngram Viewer jest interesujący? Zacznijmy od niezobowiązującej rozgrzewki: money, sex, power.
Zainteresowanie ludzkości tymi trzema tematami jest względnie stabilne, choć władza jakby nieco straciła na atrakcyjności, natomiast seks systematycznie na niej zyskuje. Wpisując nieco bardziej zaawansowane terminy związane z seksem (co pozostawiam już domyślności i wyobraźni czytelników) uzyskujemy wykres wyraźnie demonstrujący początek seksualnej rewolucji końcówki lat 60., notabene niemal identyczny z wykresem terminu „single mother”.
Ciekawie wypada również porównanie terminów men i women. Od lat 70. kobiety coraz wyraźniej zaznaczają się w literackiej spuściźnie ludzkości, a mężczyźni okazują się dla autorów coraz mniej interesujący.
Idźmy dalej, sięgając po tematy nieco poważniejsze: wojnę i pokój. Wykresy nie pozostawiają wątpliwości, który temat bardziej absorbuje ludzkość, a dwa obszary wyraźnego wzrostu częstotliwości występowania tych terminów zaznaczają pierwszą i drugą wojnę światową.
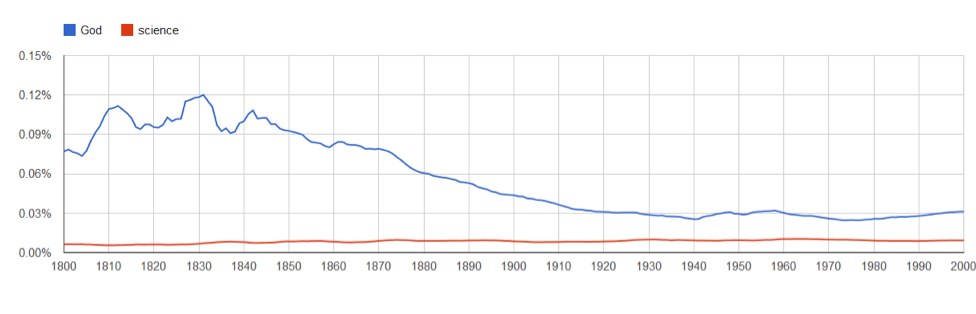
Osobom skłonnym do refleksji polecam wpisanie takich terminów jak Africa, human rights, genocide, childhood, ownership, divorce, interest rate, politics, data explosion, ecology, obesity(Afryka, prawa człowieka, ludobójstwo, dzieciństwo, własność, rozwód, stopa procentowa, polityka, eksplozja danych, ekologia, otyłość), a później dla porównania death, mercy, devotion, Jesus, punishment, penance, forgiveness(śmierć, miłosierdzie, pobożność, Jezus, kara, pokuta, wybaczenie). Mnie zainteresował Bóg i nauka.
Wykres odosobnionego terminu science wygląda bardzo obiecująco ‒ najwyraźniej zainteresowanie ludzkości nauką systematycznie rośnie. Zestawienie science,God odziera ze złudzeń. Co prawda Bóg od połowy XIX wieku jest w wyraźnym odwrocie, ale naukę nadal ma do pokonania ogromny dystans (z czystej ciekawości wpisałam God is our hope, science is our hope, ale rezultaty można sobie wyobrazić jeszcze przed uzyskaniem wyniku…). Swoją drogą Bóg traci na popularności, ale Christmas idzie w górę…
Niezwykle ciekawe rezultaty daje porównanie terminów invention, innovation, marketing.
Czyżbyśmy naprawdę epokowe wynalazki należały do przeszłości, a nam pozostał jedynie marketing innowacji?
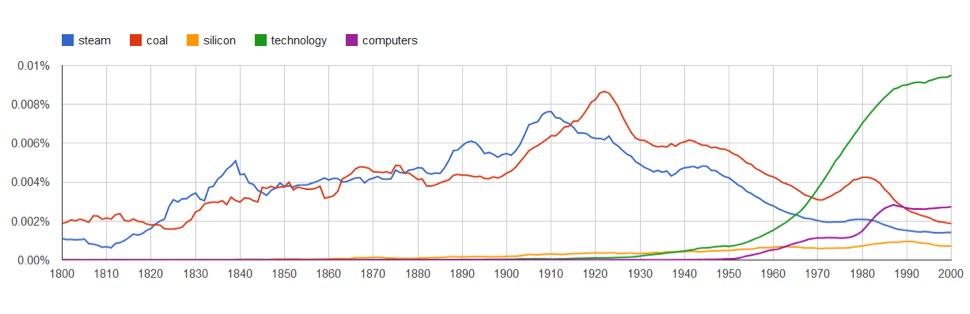
Wpiszmy zatem steam, coal, silicon, technology, computers. Czy ten niezwykle interesujący wykres świadczy o tym, że węgiel i para zawładnęły wyobraźnią pisarzy, publicystów i naukowców znacznie mocniej niż krzem i komputery? Czy to znaczy, że chociaż wydawało nam się, że żyjemy w erze komputeryzacji, dla absolutnej większości ludzi nie ma to absolutnie żadnego znaczenia?
Nasuwają mi się dwie refleksje.
Refleksja pierwsza, czyli o związku nauki z emocjami i potrzebie sprzedania opowieści o nowoczesności, jeśli chcemy w niej żyć.
Kiedy Robert Firmhofer, dyrektor warszawskiego Centrum Nauki Kopernik, inaugurował jego działalność w 2010 roku, postanowił opowiedzieć o wynalazczości, przenosząc internetowych graczy do XIX-wiecznej Warszawy, która nigdy się nie zdarzyła, ale mogła. Gra fabularna, która toczyła się przez kilka miesięcy w Internecie i w przestrzeni Warszawy, osadzona została w stylistyce steampunku, a gracze w zespołach współtworzyli kolejne odsłony życiorysów wybranych postaci, które miały do spełniania własne marzenie o nowoczesności. Graficy realizujący grę wyjaśniali wówczas, że posłużyli się stylistyką z pogranicza historii alternatywnych, science-fiction i fantasy z czasów rewolucji przemysłowej, która potoczyła się innym niż w rzeczywistości torem, kreując inne wynalazki, by sama idea wynalazczości i nauki zyskała na atrakcyjności. „Nauka jest częścią kultury i nie stoi do niej w opozycji, dlatego potrzebny jest stały dialog między sztuką i nauką. Stąd między innymi pomysł mówienia o wynalazkach za pomocą narracji gry fabularnej”- mówił wówczas Robert Firmhofer. Albert Einstein powiedział: „Wyobraźnia bez wiedzy może tworzyć rzeczy piękne. Wiedza bez wyobraźni najwyżej doskonałe. Wyobraźnia jest ważniejsza niż wiedza, bo choć wiedza wskazuje na to, co jest, wyobraźnia wskazuje na to, co będzie”. Nauka i emocje nie mogą istnieć niezależnie od siebie. Z jakiegoś powodu roboty zawładnęły naszą wyobraźnią w latach 80., by w kolejnych latach znacznie stracić na atrakcyjności. Cybernetyka straciła swój potencjał jeszcze wcześniej, na początku lat 70, podobnie jak bionika. Technologia, informatyka, Internet okazują się bardziej nośne, ale jeśli ‒ dla przykładu ‒ miasta 2.0 mają znaleźć w swoich budżetach pieniądze nie tylko na drogi, kanalizację, mieszkania komunalne i transport publiczny, ale też na powszechne Wi-Fi, to musimy przyłożyć się bardziej do sprzedania tej opowieści o nowoczesności.
Refleksja druga, czyli nie drwijmy z topornych pierwszych wersji.
Dziś narzędzia w rodzaju Ngram mogą się wydawać mało istotne, ale pamiętajmy, że rozmowa przez ciężki i nieporęczny telefon w sieci NMT w latach 90. wymagała wyczulonego słuchu, rozwiniętej wyobraźni i anielskiej cierpliwości ‒ i nie było to wcale tak dawno temu. Być może culturomics, czyli lingwistyka obliczeniowa opierająca się na tekstach w postaci cyfrowej, a mówiąc bardziej ogólnie ilościowa analiza kultury, już na przestrzeni kilku najbliższych lat rozwinie się na tyle, by przewidzenie wybuchu Arabskiej Wiosny na przełomie 2010/2011 roku nie było jednym z jej niewielu na razie sztandarowych osiągnięć. W opublikowanej w połowie 2011 roku pracy naukowej „Culturomics 2.0: Forecasting Large-Scale Human Behaviour Using Global News Media Tone in Time and Space” Kalev H. Leetaru pokazał, w jaki sposób ilościowa analiza wiadomości prasowych, radiowych i telewizyjnych w połączeniu z informacją geograficzną pozwala zobrazować nastroje w poszczególnych częściach świata. Naprawdę interesująco zrobi się wtedy, kiedy będziemy w stanie nie tylko zobaczyć, jak często w piśmiennictwie występuje słowo „wojna”, ale jak skorelowana jest ze słowami „eliminacja”, „czystość” czy „przestrzeń”; kiedy będziemy mogli zrozumieć korelację frazy „otwarcie nowego oddziału banku” z opóźnioną o kilka lat lub miesięcy frazą „bańka inwestycyjna”. Warto pamiętać, że ambicje twórców Google Books i pokrewnych projektów wykraczają daleko poza udostępnienie informacji, a coraz większe sukcesy choćby projektu Google Translate (niedowiarkom polecam wrzucenie w translate.google.com na przykład fragmentu tego tekstu, tłumaczenie z polskiego na angielski naprawdę daje klarowny obraz treści, czego jeszcze kilka lat temu nie można było powiedzieć; notabene w drugą stronę, a angielskiego na polski, nie działa to nawet w połowie tak dobrze) wskazują na to, że jeśli w ogóle jest jakaś droga do sztucznej inteligencji, to Google nią idzie. Merry Christmas!



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}