Wstrzymanie się przed krytycznym komentarzem na temat Chmury Amazonu oszczędziło mi dzisiaj wycofywania się z niego rakiem. Łatwo zwalić całą winę za ponad setkę wyłączonych serwisów na Amazon i uderzyć na trwogę, że przez awarię chmury zagrożone było ludzkie życie, jak sugerował serwis wykorzystują...
Felietony
Na szali jest życie pacjentów, ale ich fotki są bezpieczne. Awaria chmury Amazonu inaczej
{kind=link}
To cię zainteresuje Oto dlaczego nie korzystam z polskich serwisów videoKoniec blue screen of death? Takich rzeczy się nie robi!
Trafiłem dziś na interesujący artykuł prezesa serwisu SmugMug - jednego z najbardziej zaawansowanych narzędzi w sieci, służących do składowania, edycji i prezentacji zdjęć w sieci. Wyjaśnia w nim, dlaczego awaria chmury Amazon nie spowodowała większych zakłóceń w jego działaniu, choć setka innych witryn była niedostępna - w tym wspomniana infrastruktura usługi monitorującej EKG pacjentów mających problemy z sercem.
Design for failure
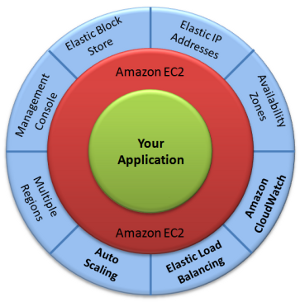
Tak Don MacAskill z SmugMug, jak i spec od rozwiązań w chmurze George Reese podkreślają, że awaria Amazon Web Services to dowód, że wadliwa jest implementacja w wykonaniu korzystających z chmury serwisów, a nie koncepcja Cloud Computing. MacAskill wyjaśnia, że kluczowe dla działania SmugMug usługi są rozłożone po kilku "strefach dostępności" (Availability Zones), które w Amazon są od siebie dokładnie odseparowane, aby awaria jednej nie wpływała na pozostałe. W wypadku krytycznych systemów, istnieje też (kosztowna) możliwość umieszczenia go w innym regionie, co gwarantuje lepsza separację i jeszcze wyższy poziom bezpieczeństwa.
Cała infrastruktura SmugMug została od początku "zaprojektowana z myślą o awarii" (design for failure). Oznacza to, że awaria jednego z komponentów serwisu nie oznacza konieczności zdjęcia całości z sieci, a tylko tymczasowy brak jednej z funkcji. Każdy z elementów infrastruktury może zostać "zabity", a system automatycznie zareaguje na awarię przerzucając obciążenie na działający komponent znajdujący się w innej "strefie dostępności". Dlatego, efekty awarii chmury Amazonu były nieporównywalne z ponad 8 godzinną awarią, z jaką SmugMug musiał się zmierzyć, gdy korzystał jeszcze z własnej infrastruktury.
Czytaj dalej poniżej
Koncepcja nie jest, ani nowa, ani rewolucyjna, ani pozbawiona wad. Jednak połączenie niższych kosztów Amazon Web Services, większa swoboda w budowaniu redundantnych serwisów "projektowanych z myślą o awarii" oraz przykład SmugMug, to z mojego punktu widzenia dowód, że pomijając oczywistą odpowiedzialność Amazon za działanie swoich usług, większość pokrzywdzonych przez awarię jest sama sobie winna. Jak widać da się to zrobić inaczej. Dlatego, to właściciele serwisów w których dostępność usługi jest absolutnie krytyczna (np. wspomniane EKG, usługi w modelu SAAS dla firm) ponoszą większa odpowiedzialność za wywołany awarią downtime niż Amazon.
Hej, jesteśmy na Google News - Obserwuj to, co ważne w techu